The knapsack problem or rucksack problem is a problem in combinatorial optimization:
Given a set of items, each with a mass and a value, determine the
number of each item to include in a collection so that the total weight
is less than or equal to a given limit and the total value is as large
as possible. It derives its name from the problem faced by someone who
is constrained by a fixed-size knapsack and must fill it with the most valuable items.
The problem often arises in resource allocation where there are financial constraints and is studied in fields such as combinatorics, computer science, complexity theory, cryptography and applied mathematics. (http://en.wikipedia.org/wiki/Knapsack_problem)
So the goal here is to program the following model.
Maximize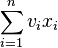
subject to
We are going to use dynamic programming technique to code the problem in python.
Input Format
A knapsack input contains n + 1 lines. The first line contains two integers, the first is the number of items in the problem, n. The second number is the capacity of the knapsack, W. The remaining
lines present the data for each of the items. Each line, i ∈ 0 . . . n − 1 contains two integers, the
item’s value v i followed by its weight w i .
Input File content Format
n W
v_0 w_0
v_1 w_1
...
v_n-1 w_n-1
The output contains a knapsack solution and is made of two lines. The first line contains two values
obj and opt. obj is the total value of the items selected to go into the knapsack (i.e. the objective
value). opt should be 1 if your algorithm proved optimality and 0 otherwise. The next line is a list
of n 0/1-values, one for each of the x i variables. This line encodes the solution.
the solver.py file contains the code that implements the dynamic programming way of knapsack problem. solver.py
The problem often arises in resource allocation where there are financial constraints and is studied in fields such as combinatorics, computer science, complexity theory, cryptography and applied mathematics. (http://en.wikipedia.org/wiki/Knapsack_problem)
So the goal here is to program the following model.
Maximize
subject to
We are going to use dynamic programming technique to code the problem in python.
Input Format
A knapsack input contains n + 1 lines. The first line contains two integers, the first is the number of items in the problem, n. The second number is the capacity of the knapsack, W. The remaining
lines present the data for each of the items. Each line, i ∈ 0 . . . n − 1 contains two integers, the
item’s value v i followed by its weight w i .
Input File content Format
n W
v_0 w_0
v_1 w_1
...
v_n-1 w_n-1
The output contains a knapsack solution and is made of two lines. The first line contains two values
obj and opt. obj is the total value of the items selected to go into the knapsack (i.e. the objective
value). opt should be 1 if your algorithm proved optimality and 0 otherwise. The next line is a list
of n 0/1-values, one for each of the x i variables. This line encodes the solution.
the solver.py file contains the code that implements the dynamic programming way of knapsack problem. solver.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
from collections import namedtuple
Item = namedtuple("Item", ['index', 'value', 'weight'])
def solve_it(input_data):
# parse the input
lines = input_data.split('\n')
firstLine = lines[0].split()
item_count = int(firstLine[0])
capacity = int(firstLine[1])
items = []
for i in range(1, item_count+1):
line = lines[i]
parts = line.split()
items.append(Item(i-1, int(parts[0]), int(parts[1])))
value = 0
weight = 0
taken = [0]*len(items)
#create [2 by capacity+1] dimensioned capacity matrix
#use dynamic programming
n_rows=capacity+1
n_cols=item_count+1
cap_matrix = [[0]*(2) for i in range(n_rows)]
for col_item in range(1,n_cols):
for row in range(1,n_rows):
if items[col_item-1].weight <= row:
#check if not taking current item yields in a better value
cap_matrix[row][1] = max(cap_matrix[row-items[col_item-1].weight][0] + items[col_item-1].value, cap_matrix[row][0])
else:
#our item doesnt fit yet get the value of previous item
cap_matrix[row][1] = cap_matrix[row][0]
f = open("helper.txt", "w")
f.write(mylist)
#set the optimum value
value = cap_matrix[n_rows-1][n_cols-1]
#print the capacity matrix
#print('\n'.join([''.join(['{:4}'.format(item) for item in row])
# for row in cap_matrix]))
#lets traceback to see which items are taken
n_cols = n_cols-1
n_rows = n_rows-1
while(n_rows>0 and n_cols>0):
if(cap_matrix[n_rows][n_cols] != cap_matrix[n_rows][n_cols-1]):
n_cols = n_cols-1
taken[n_cols] =1 #item selected
n_rows = n_rows - items[n_cols].weight #decrease capacity by items weight
else:
n_cols = n_cols-1
taken[n_cols] =0
# prepare the solution in the specified output format
output_data = str(value) + ' ' + str(0) + '\n'
output_data += ' '.join(map(str, taken))
return output_data
import sys
if __name__ == '__main__':
if len(sys.argv) > 1:
file_location = sys.argv[1].strip()
input_data_file = open(file_location, 'r')
input_data = ''.join(input_data_file.readlines())
input_data_file.close()
print solve_it(input_data)
else:
print 'This test requires an input file. Please select one from the data directory. (i.e. python solver.py ./data/ks_4_0)'