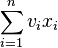You can use any of the following decorators to profile your functions line by line. The first one(Profiler1) is a decorator as a class and the second one(Profiler2) is a decorator as a function example. What each one does is as follows: They take a function to run as an argument, they run the function with its parameters and the cProfile module analyzes that function as it runs. After profiler finishes analyzing, it prints out the results ordered by the cumulative time passed during execution of that function. To run the profiler on a function just write @ClassLineProfiler or @fun_line_profiler above the function definition you want to analyze. See example below.
Code with sample usage:
Code with sample usage:
import cProfile
import pstats
import StringIO
import numpy as np
# Profiler1
class ClassLineProfiler(object):
def __init__(self, fn):
self.fn = fn
def __call__(self, *args, **kwargs):
pr = cProfile.Profile()
pr.enable()
retVal = self.fn(*args, **kwargs)
pr.disable()
s = StringIO.StringIO()
sortBy = 'cumulative'
ps = pstats.Stats(pr, stream=s).sort_stats(sortBy)
ps.print_stats()
print(s.getvalue())
return retVal
# Profiler2
def fun_line_profiler(fn):
def wrapper(*args, **kwargs):
pr = cProfile.Profile()
pr.enable()
retVal = fn(*args, **kwargs)
pr.disable()
s = StringIO.StringIO()
sortBy = 'cumulative'
ps = pstats.Stats(pr, stream=s).sort_stats(sortBy)
ps.print_stats()
print(s.getvalue())
return retVal
return wrapper
# Linear Forward Pass
def forward(x, w):
return x * w
# Loss function
def loss(x, y, w):
y_pred = forward(x, w)
return (y_pred - y) ** 2
# @fun_line_profiler
@ClassLineProfiler
def run_linear_neural_network():
x_data = np.array([1.0, 2.0, 3.0])
y_data = np.array([2.0, 4.0, 6.0])
N = x_data.size + 1
for w in np.arange(0.0, 4.1, 0.1):
print("w=", w)
l_sum = 0
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val, w)
loss_val = loss(x_val, y_val, w)
l_sum += loss_val
print("x:{}, y:{}, y_pred:{}, loss:{}".format(
x_val, y_val, y_pred_val, loss_val))
print("MSE=", l_sum / N)
run_linear_neural_network()